Discover why most enterprise AI initiatives collapse without scalable data architecture and data lineage – and what your organization needs to build AI that actually works.
Let’s be honest for a second.
Your organization has probably spent a significant amount on enterprise AI already. Maybe it was a promising pilot. Maybe a vendor demo that had the whole leadership team nodding enthusiastically. Maybe an initiative that generated a lot of internal buzz – and then quietly disappeared from the quarterly roadmap.
You’re not alone. And it’s not your fault.
But here’s the thing nobody in that vendor demo told you: the AI was never the problem. The data underneath it was.
Imagine hiring the world’s best chef and handing them expired ingredients. Doesn’t matter how talented they are – the meal is going to be bad.
That’s exactly what happens when enterprises deploy sophisticated enterprise AI solutions on top of broken, siloed, or unverified data. The model isn’t the bottleneck. The data architecture is.
And yet, most organizations rush to pick the AI platform before they’ve even looked at the pipes carrying data into it. It’s like building the penthouse before checking if the foundation can hold it.
Over 80% of enterprise AI projects never make it to production. Ask anyone who’s lived through one of those failures – they’ll almost always trace it back to data. Inconsistent formats. Duplicate records. No idea where the data actually came from or whether it can be trusted.
That last part is what data lineage is all about – and it’s the piece most enterprises skip entirely.
Think of data lineage as a paper trail for your data. Every time a piece of data moves, gets cleaned, gets transformed, or gets combined with something else – lineage records it. Where it started, what happened to it, and where it ended up.
Why does that matter for enterprise AI? Because when your model spits out a recommendation that makes no sense, someone has to go find out why. Without lineage, that investigation is a nightmare. With it, you can trace the exact chain of events that led to the bad output and fix it at the source.
It also matters enormously for compliance. GDPR, CCPA, and a growing list of sector-specific regulations require organizations to know where personal data lives and how it’s being used. If you can’t answer that question, data lineage isn’t just useful – it’s legally necessary.
And honestly? It matters for trust. Your CFO or Chief Risk Officer isn’t going to act on an AI-generated insight they can’t verify. Give them an audit trail and suddenly AI stops being a black box. That’s when adoption actually happens.
Without lineage baked into your ai governance strategy, you’re asking people to trust something they have no reason to trust.
Scalable data architecture is the infrastructure your AI actually travels on. Picture it like a highway system.
If the roads are narrow, full of potholes, and built for a city a tenth of the size – the moment traffic picks up, everything grinds to a halt. That’s what happens to ai infrastructure that wasn’t designed to scale. It works fine in a controlled pilot. The moment it hits real-world data volumes, it collapses.
A properly built scalable data architecture does a few non-negotiable things:
Here’s where a lot of enterprises get it wrong – they treat ai governance like a compliance checkbox. Something you do after the fact to satisfy an audit or a legal requirement.
That mindset is expensive.
Data governance tools aren’t bureaucratic overhead. They’re the systems that make sure data is classified correctly, accessed only by the right people, and meets quality standards before it ever touches a model. The best data governance software doesn’t slow teams down – it quietly works in the background, flagging anomalies, enforcing standards, and logging everything automatically.
When governance is reactive, you’re already behind. The model has trained on unreliable data. The outputs are already in front of decision-makers. Walking that back is painful, and sometimes impossible.
When it’s proactive and embedded into enterprise data management from the start, you’re protected before problems happen – not scrambling after them.
Let’s put numbers to it, conceptually at least.
Every failed AI pilot means rework. Rework means budget. It also means burned goodwill – with the business stakeholders who were sold on AI’s potential and now quietly don’t believe in it anymore. Rebuilding that trust is harder than building the right infrastructure in the first place.
There are also compliance costs. Regulatory fines for mishandled data are real and growing. And there’s the opportunity cost of competitors who did get their scalable data architecture right and are now moving faster because of it.
Organizations that invest properly in data foundations before scaling their enterprise ai solutions consistently see faster deployment timelines, higher model accuracy, and stronger executive buy-in. Not because they got lucky – because they built the right way.
You don’t have to overhaul everything at once. Start with clarity:
The enterprises that are actually winning with AI right now aren’t necessarily the ones with the biggest budgets or the flashiest enterprise ai platforms. They’re the ones that did the boring, unglamorous foundational work first.
They invested in data architecture that scales. They built data lineage into the pipeline from day one. They treated ai governance as a core capability, not a compliance afterthought. And they used data governance tools to make sure the data feeding their models was clean, verified, and traceable.
That’s not a technology story. That’s a discipline story.
Get the foundation right – and AI stops being something that sounds good in a presentation. It becomes something that actually changes how your business operates.
The most common reason is weak data architecture. When data is siloed, inconsistently formatted, or impossible to verify, even the most advanced enterprise AI solutions can’t produce reliable outputs. The technology isn’t the bottleneck – the data infrastructure underneath it is.
Data lineage is a complete record of where data came from, how it was processed, and where it ended up. For enterprise ai platforms, this is essential – it enables faster debugging, supports regulatory compliance, and gives business leaders the audit trail they need to actually trust AI-generated insights.
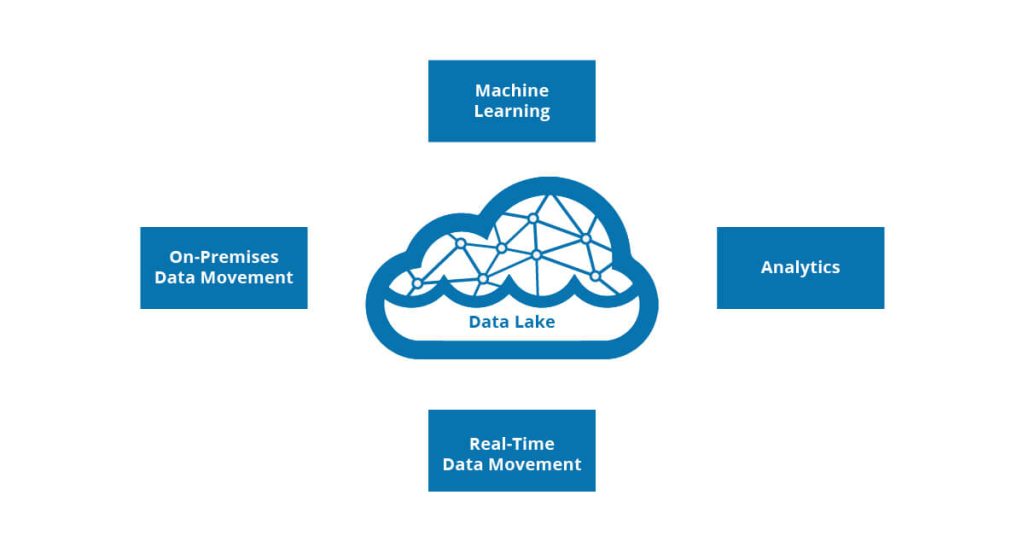
Scalable data architecture ensures that data pipelines don’t break when workloads grow. It standardizes data access across the organization, enables real-time data flow, and gives ai infrastructure the flexibility to expand alongside evolving business needs – without constant rebuilding.
The best data governance software integrates seamlessly with existing systems, automates quality checks and access controls, and works proactively – catching issues before they reach the model. It should reduce governance burden on teams, not add to it.
Start with an honest audit of your current data landscape. Understand what you have, where it lives, and how it flows. From there, implement data lineage tracking, choose data governance tools that fit your stack, and design your scalable data architecture with future AI workloads already in mind.