Discover how mastering data lake architecture can unlock AI readiness for B2B enterprises. Learn the difference between data lake vs data warehouse.
Picture this: your sales team is chasing a lead that your CRM flagged as cold six months ago. Meanwhile, that same prospect has visited your pricing page four times this week, downloaded two whitepapers, and attended your last webinar. That signal exists somewhere in your data. But nobody saw it – because nobody could see it. It was buried across three disconnected systems, in three different formats, with no one responsible for connecting the dots.
This isn’t a hypothetical. It’s Tuesday morning at thousands of B2B companies right now.
The frustrating part? The data was always there. The problem was never a lack of information – it was a lack of infrastructure to actually use it. And that’s precisely why data lake architecture has become one of the most important conversations in enterprise technology today.
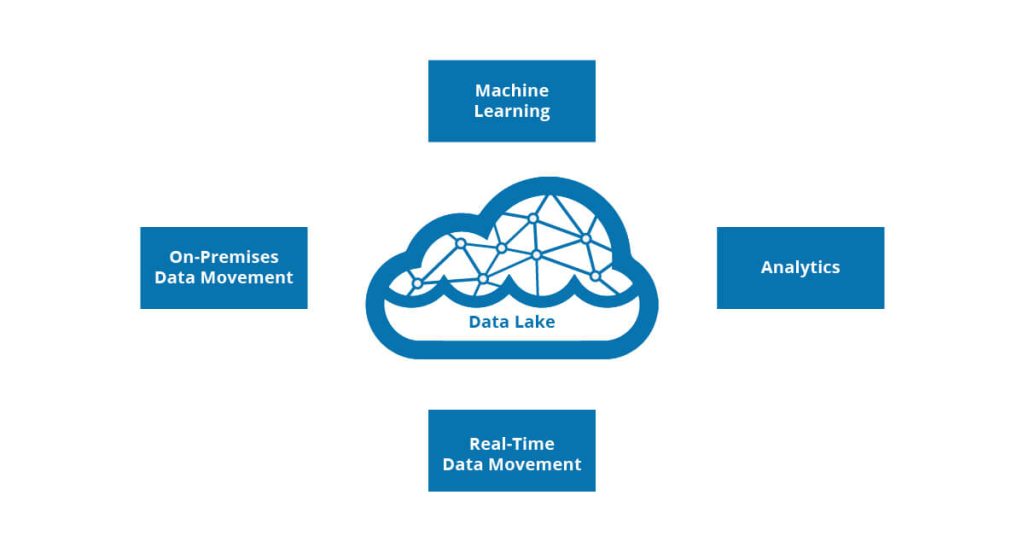
Think of a data lake the way you’d think of an actual lake. Rivers, streams, and rainfall all pour into it – from different directions, in different forms, at different times. The lake holds all of it. You don’t need to sort it before it arrives. You don’t need to pre-label it. It just flows in, and sits there, ready to be drawn from whenever you need it.
That’s data lake architecture in a nutshell.
It’s a centralized system that stores data in its raw, native format – structured spreadsheets, messy JSON logs, audio files, sensor telemetry, you name it – at massive scale. The brilliance is in the flexibility. You’re not forced to decide how you’ll use data before you store it. You store it, and let your future use cases determine the shape.
For B2B enterprises wrestling with exploding data volumes across CRMs, ERPs, marketing platforms, and third-party feeds, that flexibility isn’t just convenient – it’s essential to any serious big data architecture strategy.
If you’ve spent any time in data strategy discussions, you’ve probably heard people argue passionately for one over the other. Here’s the honest truth – it’s not really a competition.
In the classic data lake vs data warehouse framing, a warehouse is structured, fast, and optimized for answering questions you already know you’ll ask. Your finance team running monthly revenue reports? That’s a warehouse job. It’s clean, reliable, and purpose-built.
A data lake, on the other hand, is where you go when you’re still figuring out the questions. It stores raw, unprocessed data without demanding a schema upfront. It’s exploratory. It’s broad. It’s where your data scientists live when they’re hunting for patterns nobody’s looked for yet.
The problem most enterprises run into is that they pick one and try to force-fit every use case into it. That’s where enterprise data management starts to unravel. You end up with either a rigid warehouse that can’t handle new data types, or a chaotic lake where no one can find anything useful.
Which brings us to the architecture that’s quietly becoming the new standard.
The data lakehouse is genuinely one of those rare ideas where the name actually tells you everything. It’s a hybrid – and a smart one.
It takes the raw storage flexibility of a data lake and layers on the structure, reliability, and query performance of a warehouse. You get ACID transactions (meaning your data stays consistent even when multiple processes are touching it). You get schema enforcement where you need it. You get BI dashboards running fast, right alongside the exploratory ML pipelines your data team is building.
For B2B organizations where mastering data means different things to different teams – the analyst who needs a clean report by Friday and the data scientist who’s training a churn model – the data lakehouse stops the tug-of-war. Everyone works from the same foundation.
Platforms like Databricks, Delta Lake, and Snowflake have made this surprisingly accessible, even for organizations that aren’t running Silicon Valley-sized engineering teams.
Nobody gets excited about data governance. It doesn’t make for a compelling conference keynote. It doesn’t show up in the shiny AI product demos. But you know what it does? It’s the difference between an AI model your team actually trusts and one that quietly makes bad recommendations nobody can explain.
Here’s the real problem with skipping governance: garbage in, garbage out. If your data lake architecture is pulling from sources that are inconsistent, duplicated, or poorly labeled, your downstream AI and analytics outputs will reflect that. And in B2B, where decisions involve real money, real contracts, and real relationships, “our model was trained on messy data” is not a defence anyone wants to give.
Data governance is what defines who owns the data, who can see it, how long you keep it, and how you handle it across compliance requirements like GDPR or HIPAA if they apply to you. It’s the rulebook your big data architecture runs on. Build the lake first and add governance later, and you’ll be rebuilding – or worse, firefighting – within 18 months. Get it right upfront, and it quietly holds everything together.
There’s a reason almost every serious data lake architecture conversation today starts with cloud. It’s not trend-chasing – it’s pragmatic.
A well-built cloud data platform gives you something on-prem infrastructure fundamentally can’t: elasticity. Your storage and compute scale with your business, not the other way around. You’re not buying servers in anticipation of data volumes you might hit in three years. You spin up what you need, when you need it.
Beyond cost efficiency, the native integrations are genuinely compelling. AWS with S3 and Glue, Azure Data Lake Storage paired with Synapse Analytics, Google Cloud Storage and BigQuery – these aren’t just storage solutions. They’re ecosystems with ML tooling, real-time ingestion pipelines, security controls, and compliance certifications built in.
For enterprise data management at scale, that ecosystem approach is what lets your data infrastructure grow with your AI ambitions rather than becoming the bottleneck for them.
Here’s what the most data-mature B2B organizations figured out early: mastering data isn’t something you finish. You don’t hit a milestone, check it off the roadmap, and move on. It’s an ongoing discipline – one that requires the right architecture, the right governance model, the right team culture, and the willingness to revisit decisions as your business evolves.
The enterprises leading with AI right now didn’t get there by throwing money at tools. They got there by doing the foundational work – building a data lake architecture that was genuinely governed, choosing a cloud data platform that scaled with them, and knowing clearly when to lean on a data lakehouse model versus simpler approaches.
Your data is already telling a story. The question is whether your infrastructure is set up to hear it.
Whether you’re just starting to weigh data lake vs data warehouse options or you’re actively evolving toward a data lakehouse model, the strategic priority is the same: build a data lake architecture that’s clean, governed, and ready for whatever AI ambitions come next. The foundation you lay today is directly what your competitive intelligence, customer experience, and revenue forecasting will run on tomorrow. That’s not infrastructure for IT – that’s infrastructure for growth.
Data lake architecture is a centralized storage approach that holds raw data in its native format – structured or otherwise – until it’s ready to be analyzed. For B2B enterprises, it creates the flexibility to store diverse data from multiple sources, making it the foundation for scalable AI and analytics programs without forcing premature decisions about data structure.
The data lake vs data warehouse distinction comes down to structure and intent. A warehouse holds clean, processed data optimized for known queries – great for reporting. A data lake stores raw, unprocessed data for exploratory use – great for discovery. Neither replaces the other; most mature enterprises use both, or adopt a data lakehouse hybrid that bridges the two.
A data lakehouse adds structure and transactional reliability on top of raw data storage. You get the breadth of a data lake with the performance and consistency of a warehouse – which makes mastering data across both BI and ML use cases far more practical without maintaining two separate systems.
Because big data architecture without data governance is just organized chaos. Governance defines ownership, access, quality standards, and compliance rules – and all of that directly impacts how much you can trust the AI models and analytics built on top of your data. It’s not glamorous work, but skipping it is one of the most expensive mistakes enterprises make.
A cloud data platform removes the ceiling on your storage and compute while adding real-time ingestion, native ML integration, and built-in compliance controls. For enterprise data management, that means your data infrastructure grows with your business rather than becoming the thing holding your AI strategy back.