Learn how data lineage secures AI data lakes, prevents breaches, and enforces governance. A complete guide to metadata management and zero trust data security.
Your data lake holds everything-customer records, financial data, proprietary models, transaction histories. It’s a goldmine of insights for AI and business intelligence. It’s also a potential liability the moment you can’t track where every piece of data came from, who touched it, or how it’s being used.
This is where data lineage becomes non-negotiable.
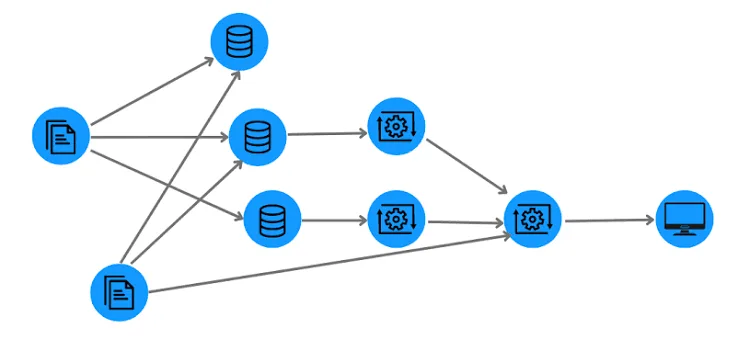
Data lineage isn’t a new concept, but in today’s AI-driven landscape, it’s evolved into a critical pillar of data security and compliance. It’s the ability to see the complete path of every dataset-from source systems to storage, transformation, and consumption. In an AI data lake, where data flows across multiple models, teams, and applications, data lineage isn’t just useful. It’s your strongest defense.
An AI data lake accumulates data from dozens of sources: APIs, databases, third-party services, data warehouses, real-time streams. Without data lineage, you’re operating blind. You don’t know if that dataset was validated. You don’t know if sensitive information leaked into training data. You don’t know if a compromised source poisoned your models.
Data lineage for AI solves this by creating a transparent record of data movement and transformation. Here’s why it matters:
When you implement data lineage, every transformation is logged. Every join, filter, aggregation, and enrichment leaves a traceable path. This visibility is foundational to data governance frameworks that actually work. Instead of trusting that “someone” followed protocol, you can verify it-automatically.
Metadata management tools that track data lineage give you real-time insights into data quality and origin. Teams can instantly answer “Is this dataset trustworthy for this model?” rather than guessing.
AI models are only as good as their training data. If malicious actors inject bad data into your pipeline, your model degrades silently-sometimes for weeks before anyone notices. With data lineage for AI, you can trace anomalies backward. If model performance drops, you can isolate which source contributed the problem data, when it entered the system, and what downstream models it affected.
This is particularly critical in regulated industries where data security audits demand proof of data integrity.
Regulators don’t care that compliance is “hard.” They want proof. GDPR, HIPAA, SOC 2, and industry-specific mandates all require documented data governance frameworks. Data lineage is how you provide that proof at scale.
When someone requests a data subject access request (DSAR) or demands an audit trail, data lineage lets you pull together documentation in minutes instead of days. You can show exactly which systems stored personal data, for how long, and who accessed it-meeting compliance requirements without manual digging.
Zero trust security assumes nothing is inherently trustworthy-not even internal data. Every access, transformation, and consumption is verified. Data lineage is the technical foundation of zero trust data policies. You don’t grant blanket access to datasets. Instead, you track every single interaction and enforce rules based on data sensitivity, user role, and business context.
When a breach or data quality issue surfaces, time matters. Data lineage lets security and data teams respond in hours instead of days. You can immediately identify:
This speed directly reduces breach costs and regulatory fines.
Companies without robust data lineage tracking often discover problems too late. A data scientist might unknowingly train a model on corrupted data. Sensitive information might leak into non-sensitive datasets. A third-party data source might be compromised without anyone realizing downstream systems are consuming poisoned data.
These scenarios aren’t hypothetical. They happen regularly in enterprise data management environments where teams scale faster than governance does.
The cost isn’t just regulatory. It’s reputational. It’s operational-rebuilding models, auditing systems, notifying customers. It’s competitive-while you’re fixing data problems, competitors with mature data governance frameworks move faster.
Implementing data lineage for AI doesn’t require a complete infrastructure overhaul. Start with these fundamentals:
Companies with mature data lineage implementations move faster with more confidence. Data scientists spend less time validating sources and more time building models. Security teams sleep better. Compliance audits become straightforward.
The organizations winning in AI aren’t just those with the most data. They’re the ones who know what they have, where it came from, and who’s using it. Data lineage is how you get there.
Your AI data lake is an asset. Data lineage is how you protect it.
Data lineage is a complete record of how data moves through your systems-from origin through transformation to consumption. It documents every step: where data comes from, how it’s processed, where it’s stored, and who accesses it. Think of it as a detailed audit trail that answers “Where did this data come from?” and “What’s downstream of it?” This foundation of metadata management is essential for data security and compliance.
AI models depend entirely on training data quality. Data lineage for AI ensures you know exactly which sources fed your models, whether that data was validated, and if any corruption occurred. Without it, you can’t explain model decisions to regulators, you can’t detect data poisoning attacks, and you can’t respond to quality issues. It’s the difference between trustworthy AI and models you can’t defend.
Data lineage enables rapid incident response, prevents unauthorized access by tracking all interactions, supports compliance audits with documented evidence, and detects anomalies by showing which data changed unexpectedly. In a zero trust security model, data lineage is your verification mechanism-nothing is trusted implicitly; everything is logged and auditable.
An AI data lake is a centralized repository that consolidates data from multiple sources to feed machine learning pipelines and analytics workloads. Unlike traditional data lakes, an AI data lake is optimized for AI consumption-schema flexibility, rapid ingestion, integration with ML frameworks, and governance at scale. It’s where raw data becomes training data.
A strong data governance framework ensures data quality, enforces security policies, enables compliance, reduces model bias by documenting data sources, accelerates AI deployment by removing validation bottlenecks, and protects your organization from regulatory fines and reputational damage. Data lineage is the technical backbone that makes governance enforceable at scale.